
1. 調査の背景と目的
近年、ChatGPTやGoogle GeminiなどのAIチャットボットは人々の日常の情報源として利用が広がっています。しかし、チャットボットがニュースに関する質問に答える際に事実誤認や誤報を含むことが指摘されていました。例えば、AIが虚偽の事実(いわゆる「ハルシネーション」)を生成したり、引用元を誤って示したりする問題が報告されていました。こうした背景から、AIチャットボットのニュース回答の信頼性を客観的に評価する必要が生まれました。
本調査は、その目的を達成するために2025年10月に発表された大規模研究に焦点を当てています。この研究はユーロピアン・ブロードキャスティング・ユニオン(EBU)と英国放送協会(BBC)が主導し、22の公共放送局(PSM)が参加した国際的な調査です。研究の目的は、AIチャットボットがニュースに関する質問にどれほど正確に答えているかを検証し、誤報や誤解を生む要因を明らかにすることでした。これにより、AI時代における新聞や放送など信頼できる情報源の重要性や、ユーザーがAIを使った情報検索時の注意点などを示すことが期待されています。
2. 調査の方法と参加機関
本調査は、世界的に最大規模の研究と位置付けられるもので、以下のような方法で実施されました。
- 調査対象となるAIチャットボット: OpenAI社のChatGPT、Microsoft社のCopilot、Google社のGemini、およびPerplexity AIという4種類の主流のAIチャットボットが対象です。これらは世界中で利用が広く、「AIチャットボット」と言えばまず思い浮かぶモデル群です。
- 質問の種類と範囲: 調査参加機関のジャーナリストが一般的なニュースに関する質問を作成し、AIに回答を求めました。具体的な質問例としては、「ウクライナの鉱物取引協定とは何か?」「トランプ氏は3期目の大統領選挙に再選候補できるのか?」など、当時世界で議論されていた話題に関するものが挙げられています。このように各国の現時事に関する質問を用意し、AIに回答を生成させました。
- 回答の評価: 各AIが生成した回答は、プロのジャーナリストによって評価されました。評価基準には、回答の正確性(事実の正誤)、引用元の提示(出典の明示)、意見と事実の区別、背景情報の提供などが含まれました。評価者は回答を自身の専門知識や信頼できる情報源と照らし合わせ、回答に大きな問題があるかを判定しました。この評価プロセスは「ブラインドテスト」的に行われ、評価者はどのAIが生成した回答か分からない状態で評価しました。
- 参加機関と規模: 参加した公共放送局は18か国・22機関に及びます。各国では主な放送局が参加しており、例えばイギリスではBBC、ドイツではARD・ZDF・DW、フランスではRadio France、スペインではRTVE、アメリカではNPR、スイスではSRF、ウクライナではSuspilneなど、それぞれの国の信頼されたメディアが関与しました。調査ではこれら参加機関のジャーナリストが連携し、合計3,000件以上のAI回答を評価しました。
この研究の参加機関は世界中の主要な公共放送局であり、調査方法も専門家による厳密な評価であるため、信頼性の高いデータとして扱われています。
3. 調査結果の主要なポイント
本調査の結果、AIチャットボットの回答は全体の約45%に大きな誤りが含まれているとの結論が出ました。これは、「AIがニュースを誤報している」ことを意味するもので、以下のグラフが示すように、約半分の回答に少なくとも一つの重大な問題が発見されました。
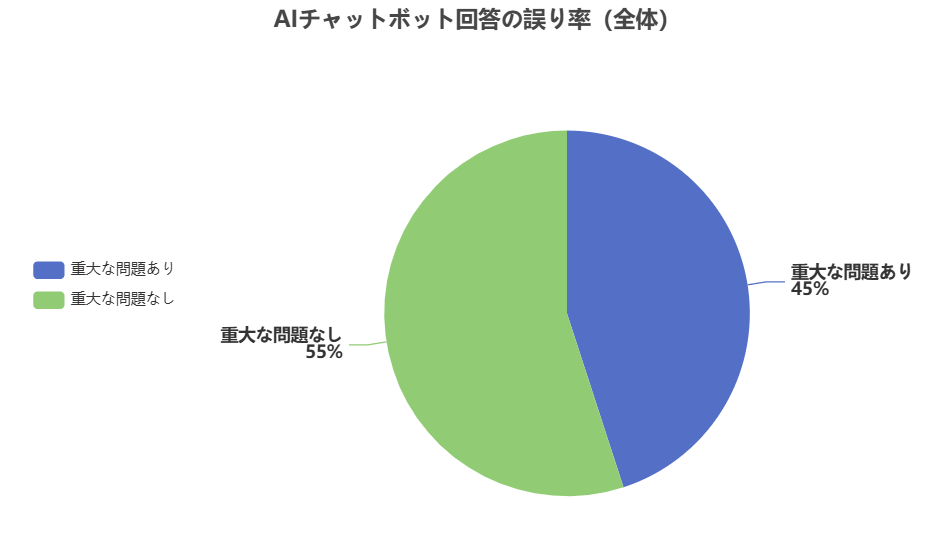
この45%という数字は、AI回答の信頼性が非常に低いことを示しています。以下に主な結果を項目別に整理します。
- 誤報の頻度: 全回答の約45%に重大な誤りが確認されました。これは、回答の半分にも満たないがかなり高い割合であり、「AIチャットボットはニュースに関する質問に正しく答えるのは稀」ということを意味します。
- 誤りの種類別: 誤りはいくつかのカテゴリに分類できます。その内訳は以下の通りです。
- 出典(引用)の問題: 回答に引用元が記載されていない、誤った出典を示している、出典が関連しないなどの出典に関する重大な問題が見られた回答は31%でした。これは、AIが情報の出典を適切に示していないことが非常に多いことを意味します。
- 事実の誤り: 事実関係に関する誤り(例えば虚偽の情報を含む、事実を誤って表現している、時期を誤っているなど)がある回答は20%でした。この20%には、AIが実在しない事実(ハルシネーション)を作り出す場合や、古い情報をそのまま使っている場合などが含まれます。
- その他の問題: 上記以外にも、回答が不適切な意見を混入している、関連しない情報を含む、明確な事実と意見の区別ができていないなどの問題も確認されました。しかし、これらの問題は45%全体から出典・事実の誤りを引いたもので、約14%程度と推測されます(詳細は調査報告書による)。
- AIモデル別の性能: 各AIチャットボットの誤り率を比較すると、GoogleのGeminiが最も性能が劣ることが分かりました。Geminiは回答の76%に重大な問題があり、他のAIの2倍以上の高い誤り率を示しました。特にGeminiの誤りの大半は出典の問題に起因していました。一方、OpenAIのChatGPTやMicrosoftのCopilot、Perplexity AIはそれぞれ約30~40%程度の誤り率で、Geminiほど高くはありませんでした。もっとも、これらChatGPTやCopilotにも出典の誤りや事実の誤りが含まれており、どのAIも完全に信頼できるとは言えないことが示されています。
以上の結果から、本調査はAIチャットボットのニュース回答には根強い誤りが多く存在することを示しています。特に出典への不適切な扱いや事実の誤認が頻発しており、これはAIがニュースに関する質問に答える際の大きな問題点となっています。
4. AIチャットボットの誤報の種類と例
調査で見つかったAIチャットボットの誤報・誤解の種類には、以下のようなものがあります。
- 虚偽の事実(ハルシネーション): AIが存在しない事実を捏造して答えることがあります。例えば、調査ではポプス(教皇)に関する誤答が報告されています。あるAIが回答した中に「ポプス・フランシスコは現教皇である」という記述がありましたが、これは教皇フランシスコが既に数ヶ月前に亡くなっていたにもかかわらずの誤答でした。このように、AIがニュースの内容を正しく把握せずに虚偽の情報を生成している例があります。
- 古い情報の使用: AIの学習データには最新の情報が含まれていない場合があり、古い事実をそのまま使ってしまうことがあります。調査では法律の改正内容を誤って答えた例が挙げられています。GoogleのGeminiが生成した回答の中に、「使い捨てバッテリー(バペ)の法改正について、2024年1月1日から新たな規制が導入された」という内容がありました。しかし実際には、その改正は2023年1月1日から施行されており、Geminiの回答は事実と異なる時期を示していました。このように、AIが古い情報を参照してしまい、回答の時期が古くなっている問題も確認されました。
- 出典の誤り(引用元の不適切な扱い): AIは回答の中で引用元を示すことがありますが、出典が関連しない、出典を偽って示す、出典が存在しないといった不適切な扱いが頻発しました。調査では、引用元が明記されていない回答が全体の10%以上あったとの指摘もあります。また、ニュース記事から引用したと誤って記載しているのにその記事にその引用がない場合も確認されています。例えば、BBCの記事の内容をAIが要約した際に、「BBCが報じた」という言葉を添えて回答していることがありましたが、その引用が実際のBBC記事に存在しなかった場合がありました。このように出典への不適切な扱いはAI回答の大きな問題点であり、ユーザーがAIから得た情報を信じてもその情報の出典が不正確である可能性が高いことを示しています。
- 意見と事実の区別ができない: ニュースには事実部分と主観的な見解部分が混在しますが、AIは意見を事実として伝えてしまうことがあります。また、過去のニュースと現在のニュースを正しく区別できず、古い情報を最新のものとして提示してしまうこともありました。例えば、AIがある質問に答える際に、「これは昨日のニュースです」といった表現を使っていましたが、実際には数週間前の情報であったという指摘もあります。このように、AIがニュースの時系列や客観性を正しく把握できていないことが確認されています。
- その他の誤解: その他にも、AI回答には関連しない情報を入れ込む(ユーザーの質問と無関係な内容を答える)、誇張した表現(事実より過剰に絞り込んだ表現をしている)、誤った人名や地名の記載などが見られました。例えば、あるAIがドイツの首相に関する質問に答えた際に、フリードリヒ・メルツ氏が首相になったはずのところをオラフ・ショルツ氏と誤って記載していた例が報告されています。また、北約の事務総長に関する質問に答えた際に、マルク・ルッテ首相が事務総長に就任したはずのところをジェンス・シュトルテンベルク氏と誤記していた例もありました。これらの例は、AIが人や組織の関係を誤解していることを示しており、ニュースに関する質問であっても基本的な事実関係を正しく把握できていない可能性があります。
以上のように、AIチャットボットの誤報は出典の問題、事実の誤認、意見と事実の混同など様々な形態で現れます。調査で報告された具体例からも明らかなように、AIがニュースに関する質問に答える際には誤解や誤情報を混入しやすいことが分かります。
5. 調査の信頼性と限界
本調査は大規模かつ国際的な研究であり、参加機関も専門のジャーナリストが多く関与しているため、その信頼性は高いと言えます。各AIからの回答を多数収集し、多数の評価者がそれらを客観的に評価したため、誤報の有無を検出する精度も高いと考えられます。特に、評価者が回答者をブラインドにしていた点や、複数の言語・地域で調査を行った点は、結果の一般化に寄与しています。
しかしながら、調査にはいくつかの限界も存在します。第一に、調査対象としたAIはChatGPT、Copilot、Gemini、Perplexityの4種類でした。これらは主流のモデルではありますが、世界中の多様なAIチャットボットの中から選定されたものであり、その他のAI(例えば中国発のモデルや、他のスタートアップのモデル)については検証されていません。もし他のAIにはこの調査で見られたような誤りが少ない可能性も否定できません。第二に、調査で用いた質問は「ウクライナの鉱物取引協定」や「トランプ氏の再選候補権」など、特定の話題に限定されていました。これらの話題は当時注目されていたものですが、他のニュース(例えば文化や経済など)についての回答は調査されていません。したがって、AIの誤報率は話題によって異なる可能性があります。第三に、評価者の主観による部分もあります。「重大な問題があるか」という判定は評価者の専門知識に依存しています。そのため、評価者によっては誤った誤報として見なされる回答もあれば、逆に見落とされる回答もあるかもしれません。ただし、調査報告書では45%という数字が高い精度で統計されているため、この誤差は小さいと考えられます。
また、調査には事前に行われたBBCの研究がベースとなっていました。BBCは2025年2月に初めてこの調査と同様の研究を発表しており、その後の調査ではいくらか改善が見られたものの依然として高い誤り率が確認されました。
この点については、AIモデルの改良による効果か、あるいは評価者の知見による精度向上かの区別が難しいですが、少なくとも誤り率の本質的な高さは変わっていないと言えます。
総じて、本調査は十分な信頼性を持つ結果を提示していますが、ユーザーはこの結果を受け取る際にも上記の限界を念頭に置く必要があります。AIチャットボットの誤報問題は今後も研究が進められる領域であり、今後の調査でさらに詳細な分析や他のAIモデルの検証が行われると考えられます。
6. 誤報問題への対応策と規制動向
AIチャットボットの誤報問題に対して、各国政府や国際機関は様々な対応策や規制を検討・実施し始めています。特にEU(欧州連合)では、AIに関する世界初の包括的な規制法である「EU人工知能法(AI Act)」を制定し、AI生成コンテンツの透明性や安全性を確保する枠組みを整えています。この法では、AIが生成した画像・音声・動画(いわゆるディープフェイク)については生成内容であることを明確にラベル表示することが義務付けられています。例えば、AIで偽造された政治関係者の映像や音声が流布する事態を防ぐため、その内容がAI生成であることをユーザーに通知するようになっています。また、高リスクなAIシステム(例えば金融取引や医療診断に用いられるAIなど)には厳格な事前審査や監督が求められ、AI開発者に対して透明性・説明可能性を確保する義務が課されています。このような規制により、AIが事実を誤認して出力するリスクを低減する方向で取り組まれています。
EUはまた、デジタルサービス法(DSA)という規則も2023年から施行しており、デジタルプラットフォーマー(大規模インターネット企業)に対して情報の正確性を確保する責任を課しています。DSAでは、不実情報やディスインフォメーションの拡散を防止する措置が講じられており、プラットフォーム企業は有害なコンテンツを迅速に除去することや、ユーザーに事実確認の機会を与えることなどが求められています。これらの規制により、AIが生成した誤報がSNSや検索エンジン上で広範囲に拡散することを抑えることが狙われています。
一方、各国政府や国際機関はAI開発企業への働きかけや業界の自主規制も進めています。EUでは、2023年にAI Actの施行に向けたガイドラインを策定し、AI企業に対してAIの説明可能性やバイアスの排除などの基準を提示しています。また、EBUやBBCが主導した調査では、関係するAI企業に対して透明性の向上や誤りの低減を促すよう呼びかけています。具体的には、「Facts In: Facts Out」というキャンペーンが開始され、AI企業に対して「事実が入れば事実を出す」という原則を遵守するよう求められています。このキャンペーンのメッセージは、AIが信頼できるニュースを誤用・誤報することによって公共の信頼が損なわれるため、AI企業自身がその責任を負って改善するよう促すものです。
さらに、ユーザー側に向けた対策として、メディアリテラシーの向上やAIへの知識付与が重要視されています。調査発表時にEBUの関係者は、「人々が何を信じて良いか分からなくなると何も信じなくなり、民主主義への参加意欲を減退させかねない」と警告しています。そのため、AIの誤報の仕組みを理解し、情報源を検証する力を一般市民に持ってもらうことが求められています。各国の公共放送局はメディアリテラシー教育の一環でAIに関する情報を提供し始めており、AIチャットボットの限界や注意点を一般に伝える動きも見られます。
総じて、AIチャットボットの誤報問題に対する対応は法規制と業界の自発的な改善、ユーザー教育の複合的なアプローチで進められています。EUを中心に各国が規制を強化し、AI企業も透明性と精度の向上に努めている中で、今後さらなる進展が期待されます。
7. 調査結果の社会的意義と影響
本調査の結果は、AI時代における情報環境への影響を示唆しており、社会的な意義は大きいと言えます。
第一に、信頼できる情報源の重要性が再確認されました。調査ではAIチャットボットが回答の約45%に誤りを含むという結果が出たため、ユーザーがAIから得た情報をそのまま信じていると、事実と異なる情報を広く拡散させてしまうリスクがあります。特に若年層ではAIチャットボットをニュースの代替として使う割合が高く(15歳~24歳で7%、15歳未満では15%がAIをニュース取得手段として利用)、AIの誤答がそのまま若者の知識や判断に影響を与える可能性があります。このような場合、ディスインフォメーション(誤情報)の拡散や公共の誤解を招く懸念があります。実際、AIが虚偽のニュースを生成してSNS上で広がれば、ユーザーはそれを事実と誤認して共有する可能性があります。調査結果は、AIがニュースに関する質問に答える際の信頼性が極めて低いことを示しており、ユーザー自身が情報の正確性を検証する責任が重視されるべきであることを意味します。
第二に、民主主義への影響について言及されています。EBUの関係者は、「人々が何を信じて良いか分からなくなると何も信じなくなり、民主主義への参加意欲を減退させかねない」と警告しています。これは、誤報の拡散が公共の議論や投票行動に悪影響を及ぼす可能性を示唆しています。例えば、AIが不正確な政治ニュースを提供し、多くの人がそれを誤認してしまえば、投票先の判断に影響を与えたり、公共政策に対する誤解が生まれたりする恐れがあります。調査結果は、AI時代における公共の知的生活へのリスクを示しており、情報の正確性が損なわれることは民主主義社会にとって深刻な問題であることを示唆しています。
第三に、メディア産業やAI企業への影響です。AIがニュースに関する質問に誤答する現状は、メディアの信頼性やAI企業の信頼性にも影響を与えます。調査に参加したBBCなどのメディアは、自社の記事がAIに引用される際に誤用されていることを指摘しており、メディアブランドの損傷を懸念しています。また、AI企業側も調査結果に対して対応を迫られており、AIの誤報問題は業界全体の信用を脅かす要因となっています。今後、AI企業は誤答を減らすための技術的改善や、誤答が発生した場合の透明性(例えば「この回答には誤りが含まれています」といった表示)などに取り組む必要があります。調査結果は、AIの実用性と信頼性を考える上で重要なデータとなり、メディアやAI業界が取るべき方針に影響を与えています。
最後に、ユーザー側の意識と行動への影響です。調査結果が公表されることで、多くの人が「AIはニュースに関する質問に正しく答えない」ことを認識するようになりました。これは、ユーザーがAIを使う際の慎重さを高める効果があります。例えば、従来はAIに聞いたことをそのまま信じていた人も、今後はAIの回答をそのまま受け入れず、出典を確認したり複数の情報源を比較したりするようになるかもしれません。このように、調査結果はユーザーの情報リテラシー向上につながる可能性があります。
総じて、本調査の結果はAI時代における情報環境の不安定性を浮き彫りにし、信頼できるメディアやユーザーの判断力の重要性を再確認しています。AIチャットボットの誤報問題は社会的に深刻な問題であり、その解決にはメディア業界、AI企業、ユーザー、政府が協力して対策を講じる必要があります。
8. 関連する他の調査やデータとの比較
本調査は2025年10月に行われた最新の研究ですが、AIチャットボットの誤報問題に関する他の調査やデータとも比較することが有益です。
まず、BBCの先行研究があります。BBCは2025年2月にAIチャットボットがニュースをどれほど正確に扱えるかを評価する研究を発表しています。その研究でも、ChatGPTやCopilot、Gemini、Perplexityについて評価が行われ、回答の約50%以上に重大な誤りがあるとの結果が出ました。この結果は本調査の45%と比較すると若干高めですが、AIの誤報率が非常に高いことは共通しています。また、BBCの研究ではAIがBBC自身の記事を引用した際にも誤りを混入していることが指摘されていました。例えば、AIが「BBCが報じた」として引用した文が、実際のBBC記事には存在しなかった場合などです。この点も本調査でも確認されており、AIが信頼できるメディアの情報を誤用していることが共通の問題となっています。
次に、他の国際機関の報告です。ユネスコは2023年に「ジェネレーティブAIとディスインフォメーション」に関する報告書を発表し、AIが生成する誤情報の増加を懸念しています。その中でも、ChatGPTのような大規模言語モデル(LLM)がニュースを誤解したり虚偽の情報を生成したりするリスクが述べられています。また、欧州連合外部関係総局(EEAS)は2025年3月に「外国情報操作とディスインフォメーションの脅威」に関する報告を公表し、AIを用いたディスインフォメーションの増加に言及しています。この報告では、2024年の欧州議会選挙や米国大統領選挙でAIが関与したディスインフォメーション事例が報告されており、AIが選挙に影響を与える可能性があることが指摘されています。例えば、AIが政治関係者の偽の映像や音声を生成して拡散する、AIが自動でディスインフォメーションの文章を書き出して広める、といったシナリオが報告されています。これらの報告は本調査の結果と連動し、AIの誤報問題がディスインフォメーション拡散の一因となり得ることを示唆しています。
さらに、ユーザーのAI利用状況に関するデータも参考になります。リュターズ研究所の「デジタルニュースレポート2025」によれば、世界のオンラインニュース消費者の7%がAIチャットボットをニュース取得手段として使っているとの統計があります。特に15歳~24歳の若年層では15%がAIをニュース取得に利用しており、若者ほどAIを使いやすい環境にあることが分かります。このデータは、本調査の結果(AI回答に誤りが多い)と組み合わせると、若年層がAIを誤った情報源として過度に信頼しているリスクを浮き彫りにします。実際、若年層のAI利用者の多さは、AIの誤報が社会に与える影響をより深刻にする要因となり得ます。
加えて、AIモデルごとの誤報傾向に関するデータもあります。GoogleのGeminiは本調査でも最も誤りが多かったモデルでしたが、これはGoogleのAIサービス全体の傾向とも関連します。Googleは検索エンジンでAI回答(「AI概要」)を提供していますが、その回答にも誤った内容や不適切な情報が含まれることが指摘されています。例えば、GoogleのAI概要がユーザーに「ピザをグルーで食べるべきだ」という誤った情報を提供したり、「地質学者は人間に毎日一つの岩石を食べるよう勧めている」という謎の回答を返したりする事例がありました。このように、GoogleのAIは事実誤認や謎の回答がしばしば見られる傾向があり、Geminiの誤り率が高い理由の一つとして考えられます。一方、OpenAIのChatGPTやMicrosoftのCopilotは、これまでも事実誤認や不適切な回答が報告されていました。たとえば、ChatGPTは政治的な誤解を生む回答をしたり、Copilotはプログラミングに関する質問でも誤ったコード例を提示したりするといった問題がありました。これら他の調査・データと本調査を比較すると、主要なAIチャットボットはいずれもニュースに関する質問では誤答を頻繁にしていることが分かります。そのため、AIの誤報問題は特定のモデルに限らず一般的な現象と言えます。
最後に、メディア業界の反応も比較の材料になります。本調査では、参加したメディア各社が自社の記事がAIに誤用されている点を指摘しています。また、「Facts In: Facts Out」というキャンペーンが発起され、メディア各社がAI企業に対して改善を求めています。このような動きは、AIの誤報問題がメディア産業にも影響を与えていることを示しています。他の国でも、AIが新聞記事を要約して誤解を生むことを指摘するケースがありました。例えば、ある米国の新聞は、AIが自社記事を要約した際に事実と異なる内容を書き起こしていることを検証し、AIによる誤解を解消するために対策を講じたと報告しています。これらの事例は、本調査の結果と合わせてAIの誤報問題がグローバルに注目されていることを示しています。
以上のように、本調査は他の調査やデータと互いに補完的な位置づけにあります。他の研究ではAIの誤報の可能性や社会的影響が論じられ、データではAIを使うユーザーの数やモデルごとの傾向が示されています。そして本調査は、それらを裏付ける具体的な統計的な根拠を提供しています。今後もこれらの研究を組み合わせて考えることで、AIチャットボットの誤報問題に対する理解を深めることができるでしょう。






コメント